shoki@meshuggeneh.net
Shoki 0.3.0 User's Guide
Table of Contents
Shoki is known to compile and run on OpenBSD, FreeBSD, and Linux on x86.
With the exception of the GUI, it has also been tested on OpenBSD/SPARC,
linux/SPARC and linux/AXP.
Relative paths that appear in the instructions in this document are relative
to the top of the shoki source tree. So if the source is
in /usr/local/src/shoki-0.3.0 , then the file ./misc/foo would
be /usr/local/src/shoki-0.3.0/misc/foo .
This documentation refers to shoki version 0.3.0. Users of other versions
should consult the documentation accompanying the source code of those
releases.
The short version of the installation instructions:
The following third-party libraries and applications are needed to
successfully compile shoki:
- libpcap (http://www.tcpdump.org)
-
Libpcap is included with many OS distributions.
Starting with shoki 0.3.0, you need a version of
libpcap more recent than libpcap 0.7.2. As of the
time of this writing, that means you have to use
libpcap-0.8.1 or libpcap-current.
This is required because of an error in 0.7.2
(and some earlier releases) that causes bus errors
on SPARC64, as well as a memory leak in the
pcap filter compiler.
- flex and yacc (http://www.gnu.org/software/flex/)
-
Flex (a lex(1) replacement) and yacc are available
for virtually all UNIX-like environments. They
are included with many OS distributions, including
all of the ones shoki is known to compile on.
Flex is needed (rather than lex) for support
of the -P flag.
- zlib (http://www.zlib.org)
-
Zlib is included in many OS distributions.
The following third-party libraries are needed to enable some of
shoki's features (noted below):
- fftw 2.x (http://www.fftw.org/)
-
FFTW (the Fastest Fourier Transform in the West)
is a math library for doing FFTs (Fast Fourier
Transforms)
-
Needed for: hustler(1)
- jabberd 2.x (http://www.jabber.org/)
- loudmouth (http://projects.imendio.com/loudmouth)
-
Jabber is an open instant messaging protocol,
and loudmouth is a Jabber client library in C.
Shoki can send alerts via Jabber (so an analyst
can receive alerts in their IM client).
Needed for: shoki_sez(8)
- gtk 2.x (http://www.gtk.org/)
-
GTK+ is a toolkit for programming GUIs.
-
Needed for: hustler(1)
- gtkglext 1.x (http://gtkglext.sourceforge.net/)
-
gtkglext is an extension to GTK+ that allows OpenGL
rendering in GTK widgets.
-
Needed for: hustler(1)
- Nessus (http://www.nessus.org/)
-
Nessus is a free remote vulnerability scanner. Shoki
can import Nessus reports and use the vulnerability
to evaluate the criticality of certain kinds of
events.
- Postgresql (http://www.postgresql.org)
- DBI (http://www.cpan.org)
- DBD::Pg (http://www.cpan.org)
-
Postgres is used for all the database functions
of shoki. If you do not have Postgres you will
still be able to collect and categorise network
traffic data, but most of the aggregation and
correlation functionality of shoki will be
unavailable.
-
Note that postgresql must have OpenSSL support
in order to work with the default configuration
of shoki.
-
Needed for: Database logging support
- PCRE (http://www.pcre.org/)
-
PCRE is the Perl Compatible Regular Expression
library, a regex library with syntax and semantics
similar to Perl 5's.
-
Use of pcre is optional. If pcre support is
compiled in, all widgets that support regex
searches (in filter rules) will also support
pcre search expressions.
- OpenSSH (http://www.openssh.org/)
- rsync (http://samba.anu.edu.au/rsync/)
-
OpenSSH and rsync are used to collect data from
the sensors for centralised analysis. If you're
planning on using the default shoki data collection
model, you'll need both.
- RRDtool (http://people.ee.ethz.ch/~oetiker/webtools/rrdtool/)
-
RRDtool databases are used to store derived
anomaly data (raw data is stored in the Postgres
database)
Shoki assumes that you'll be running most of the components that handle
raw data in a chroot(1) jail as an unprivileged user. By
default, that user name is `shoki'. If you want to call this user something
else or want shoki to run as an exisiting user (i.e., `nobody'), you'll
have to edit ./shoki.conf.in and change the values for
IDSUSER and IDSGRP appropriately.
Otherwise, just create a `shoki' user and group and proceed.
If you're going to be using Postgres for logging (and you should), you
will need to add the postgres user to the shoki group.
Note that some of the scripts (the ones that access the database) will
be installed setuid to the shoki user. If you're using the defaults this
should be safe: a separate shoki user which owns nothing else; all
the components installed in their own directory (/usr/local/shoki
by default); no world read or execute permissions. If you change any
of these defaults, you may wish to consider removing the setuid bit
from the scripts cve2shoki, nessus2shoki,
reporter, sid2shoki, and syslog2shoki. The
names of these scripts, along with a warning, will be displayed during
a make install.
By default, the configure script will assume that you wish to build
none of the widgets that rely on optional libraries. This means that
the defaults chosen by just doing a:
# ./configure
...will probably work out correctly for the sensor machines.
The (interesting) options for the configure script are:
- --with-pcap=DIR
-
Specify a non-default location for libpcap. May be necessary if your
OS has an older version of libpcap (in which case you'll have to compile
a newer version and point configure at it with this option)
- --with-fftw[=DIR]
-
Enable FFTW support. This is only needed for the hustler(1)
widget. Consult the Dependancies section above more
more details.
- --with-gtk[=DIR]
-
Enable GTK+ support. This is needed to compile the hustler(1)
widget. Consult the Dependancies section above more
more details.
- --with-pcre[=DIR]
-
Enable PCRE support. Allows PCRE search expressions in SEARCH filter
rules. Consult the Dependancies section above more
more details.
- --with-pgsql[=DIR]
-
Enable Postgres support. If you're expecting to do full-blown intrusion
detection with shoki, you'll want to pass this flag to the configure
script (at least on the aggregator/analysis machine(s)). Consult
the Dependancies section above more more details.
- --with-loudmouth[=DIR]
-
Enable loudmouth support. Loudmouth is a Jabber client library, used by shoki
to send alerts to IM clients. This is needed to compile the
shoki_sez(8) widget. Consult the Dependancies
section above more more details.
There are a couple of make targets of interested, presented
in the order in which they should normally be invoked:
- make
-
Compile everything
- make test
-
Run several standard test cases through the newly compiled binaries. If
any of the tests fail, it should give the of a file containing the
output of the test. Consult this file for additional details about
the cause of the failure(s).
-
The number of tests will depend on the options passed to the configure
script, so don't be surprised if make test produces different
output on the sensor machines than it produces on the aggregator machine.
- make install
-
Installs the binaries, setting their permissions. This will not overwrite
existing config files except /etc/shoki.conf , which will be backed
up as /etc/shoki.conf.old and then overwritten.
- make chroot
-
Sets up a chroot jail for the shoki widgets to run in. This should
work correctly for OpenBSD, FreeBSD, and Linux. If you're not using
one of these OSes, consult the ./misc/setup_chroot.sh script
for an example of what needs to be done. The process is pretty
straightforward; shoki doesn't need much to run.
-
If you work out the requirements for other OSes, please send the details
to shoki@meshuggeneh.net for inclusion in future releases.
- make db
-
This will create the shoki database, set up the necessary tables, and
create the stored procedures and functions needed to allow the shoki
widgets to log to Postgres.
-
The Postgres commands used to set up the database will be saved to
a file (/usr/local/shoki/tmp/shoki_db.psql by default), and
the output of the process will be saved to another
file (/usr/local/shoki/tmp/shoki_db.log). Consult them for
details if there are any errors.
Shoki allows you to log data directly to a Postgres database. It has been
tested with Postgres 7.3.x and 7.4.x, and should work with any version of
Postgres that supports the same connector API (as defined in libpq-fe.h).
In addition to Postgres and the shoki source, you will need the perl
DBI amd DBD::Pg modules (available from
www.cpan.org) for some of the scripts.
Before doing a make db, you'll need to have Postgres installed and
configured. Information on how to accomplish this can be found at
the Postgres homepage:
www.postgresql.org . Alternately, the
Postgres packages distributed with many OSes (i.e., OpenBSD, FreeBSD,
and various linux distributions) should work without additional tweaking
(mod what's described below).
Once that's done, make sure the path to the postgres libraries is in your
link path (i.e., invoke ldconfig(8) as appropriate for your OS or set
your LD_LIBRARY_PATH).
If you want to be able to import data from a shoki lexer(1) running
in a chroot jail (and this is the default behaviour), you'll have to tweak
your Postgres configuration slightly. You'll also have to set up the shoki
chroot jail itself, which is covered elsewhere (doing a make chroot
should take care of it on the supported platforms).
By default, the shoki widgets will attempt to connect to the database
over a local socket. If you want to run the lexer in a chroot jail, that means
the local socket will have to be present in the jail.
The most straightforward way to accomplish this is to edit your
postgresql.conf file (which is in your PGDATA directory,
/usr/local/pgsql/data by default). Edit the
unix_socket_directory variable to point to the tmp directory in your
shoki chroot directory. By default, shoki installs into
/usr/local/shoki, and
sets up a chroot jail in /usr/local/shoki/chroot, so if you haven't
changed any of those settings, you want to add a line to your
postgresql.conf that looks like:
unix_socket_directory = '/usr/local/shoki/chroot/tmp'
You may also want to link this back to /tmp (so Postgres applications
like psql(1) can see the local socket). You'll have to restart
Postgres before it will use the new socket.
This of course assumes that you'll be running all the widgets that need
to talk to the database on the database machine itself. If this is
not the case, you will have to set up Postgres to use SSL. Consult
the Postgres documentation for more documentation on how to do this (it
is covered in Section 16.7 of the Postgres 7.4 manual).
If you wish to disable the use of SSL for database connections, you can
define add the disable_dbssl directive to any shoki widget
config file to prevent that widget from requiring SSL. Disabling
encryption of database connections is strongly discouraged.
This section assumes that you're accepting all of the defaults for
installation paths, usernames, database names, and table names. In
other words, it assumes that you haven't hand-edited shoki.conf
to change any of these things.
In addition, it is assumed that you've already configured the Postgres
database, done a make db to set it up for use with shoki,
and that it is currently running and ready.
Finally, it is assumed that if you need to make any firewall/filter/ACL
changes to allow your aggregator machine to ssh to your sensor
machine(s), you've already taken care of them.
- Run the ./misc/setup_ssh_fu.sh script
-
This creates a ssh key for use with shoki. It also writes a sample
ssh authorized_keys file for use on the sensor machines. You
may have to tweak the hostname in the "from=" portion of the
file; the host name (or address) should be whatever the sensor
machine(s) will see the aggregator as. You may also wish to add
the full path to the rsync(1) binary to the "command=" declaration.
- Add the name of each sensor to the sensor_list file
-
By default, this file is /usr/local/shoki/etc/sensor_list . The
fully qualified domain names of the sensor machines should be added,
one per line.
- Set up the sensor machines
-
See section 1.4.2 below.
- Manually run the collector script
-
By default, this script is /usr/local/shoki/bin/collector. It
should be run by hand to verify that the aggregator can talk to the
sensor machines. If you run into any errors, you'll want to take
care of them before continuing.
- Set up cron jobs
-
Assuming the default install paths:
-
*/11 * * * * /usr/local/shoki/bin/collector > /dev/null 2>&1
*/5 * * * * /usr/local/shoki/bin/importer > /dev/null 2>&1
*/6 * * * * /usr/local/shoki/bin/reporter > /dev/null 2>&1
*/7 * * * * /usr/local/shoki/bin/archiver > /dev/null 2>&1
*/8 * * * * /usr/local/shoki/bin/generate_html > /dev/null 2>&1
-
The collector script uses rsync(1) to collect data from
the sensors listed in the sensor_list file. By default,
the new dumpfiles from each sensor will be copied into a directory called
/usr/local/shoki/central/SENSOR/queue where SENSOR is
the fully-qualified domain name of the sensor.
-
The importer script uses lexer(1) to populate the
events table of the shoki database. This is where most of the
simple signature-based NIDS stuff happens. By default, it will also
populate the counts table, which is used to compute anomaly scores.
Each dumpfile will be moved from the queue directory to
/usr/local/shoki/central/SENSOR/lexed upon successful completion,
or /usr/local/shoki/central/SENSOR/corrupt if there are any
errors.
-
The reporter script checks the events and alerts
table for new events, reports them, and then marks them as old. It
also writes new events to an rrdtool database (which tracks the total
number of events per second and the unique number of events per second).
-
The archiver script invokes the ac2rrdtool script to
compute and graph anomaly scores. When it is done, it moves dumpfiles
from the lexed directory to the
/usr/local/central/SENSOR/archive directory.
-
The generate_html script invokes the rrdtool2graph
script, the features script, and the overview script.
These create the content for the HTML overview pages. By default, the
output of these scripts will end up in /usr/local/shoki/html.
-
The comments at the top of each of these scripts contain more information
about the inner workings of each script.
- Copy the authorized_keys.sample file created above by
./misc/setup_ssh_fu.sh over to the sensor machine and save it
as ~shoki/.ssh/authorized_keys
-
Remember that the .ssh directory and its contents should have
the same UID and GID as the shoki user, and neither the directory nor
the contents should be world accessable.
-
Consult the ssh documentation for more details about the
correct permissions on the .ssh files if you have any
questions.
- Set up cron jobs for the sensor.init, sorter, and
rewriter scripts
-
Assuming the default paths:
-
3,18,33,48 * * * * /usr/local/shoki/etc/sensor.init restart > /dev/null 2>&1
0,15,30,45 * * * * /usr/local/shoki/bin/sorter > /dev/null 2>&1
5,20,35,50 * * * * /usr/local/shoki/bin/rewriter > /dev/null 2>&1
-
The sensor.init script line will cause the sensor dumpfiles
to be rotated every 15 minutes.
-
The sorter script moves closed dumpfiles from their default
location (/usr/local/shoki/chroot/dumps) to the directory where
the rewriter script will find them (/usr/local/shoki/logs).
-
The rewriter script runs through the dumpfiles and conducts
policy-based rewriting on their contents. This
is done to reduce the size of the dumpfiles, which are then
copied into the /usr/local/shoki/queue directory where they will
subsequently be collected by the aggregator machine.
- Set up an init script to run sensor.init at boot time.
-
On OSes
that use rc.local (or something similar), you just need to add
a couple of lines like:
-
if [ -f /usr/local/shoki/etc/sensor.init ]; then
/usr/local/shoki/etc/sensor.init start
fi
-
On OSes that use individual init scripts, you can use the
sensor.init script itself.
The shoki library contains logic (borrowed from the p0f project) for
passive fingerprinting of TCP data. This allows shoki to determine
(or attempt to determine) a number of facts about the source of TCP
traffic---like operating system, uptime, and distance (in number of
hops), for example.
In order for this to work, you'll have to obtain copies of the fingerprint
files from the p0f project. To do so, you'd do something like:
# cd /usr/local/shoki/etc
# wget http://lcamtuf.coredump.cx/p0f-help/p0f/p0f.fp
# wget http://lcamtuf.coredump.cx/p0f-help/p0f/p0fa.fp
# vi fp.conf
(uncommenting the syn_fingerprints and syn_ack_fingerprints lines)
As of the time of this writing, there's a single fingerprint which
isn't parsable by shoki (it appears to be a typo in the fingerprint
file), on line 584 of p0f.fp . If you run the fp(1) widget
and it complains about a syntax error, just comment out the offending line.
One of the first things you should do after getting shoki installed is
to import the CVE/CAN data into the vulnerabilities table of the shoki
database. The cve2shoki script is provided to do this for you, and the
script contains comments outlining how to obtain and import the relevant
files. That process works something like this:
# wget http://cve.mitre.org/cve/downloads/full-cve.csv
# /usr/local/shoki/bin/cve2shoki -f ./full-cve.csv
# wget http://cve.mitre.org/cve/candidates/downloads/full-can.csv
# /usr/local/shoki/bin/cve2shoki -f ./full-can.csv
If you don't have wget(1), you'll have to download the CSV files
via your favourite web browser.
The only `gotchas' in this process is that the cve2shoki script is, by
default, installed setuid to the shoki UID and the script has to be
run on the machine that's running the postgres database. So the CSV
files have to be readable by the shoki user, and they have to be on
the database machine.
Shoki uses the CVE/CAN data to identify events involving attacks against
assets which are vulnerable to the attempted exploits. In order for this
to work, the shoki assets table must contain vulnerability data for
the assets the analyst is concerned about monitoring. A script
(nessus2shoki)
is provided to import asset vulnerability data from Nessus reports.
Just run Nessus against the assets you want to monitor (consult
the Nessus documentation if you need help doing this) and output the
report in NBE format (which is the default report format). Then
run nessus2shoki with the report as input. If you saved the report
in /usr/local/shoki/tmp/nessus_report.nbe , then you'd run:
# /usr/local/shoki/bin/nessus2shoki -f \
/usr/local/shoki/tmp/nessus_report.nbe
Like the cve2shoki script, the input file needs to be readable by the
shoki user, and the script needs to be run on the database machine.
Shoki isn't distributed with any attack signatures, and that's unlikely
to change. Folks who want to run shoki with hundreds and hundreds of
signatures therefore need to get 'em somewhere else.
In the interests of satisfying signature-count fetishists, shoki provides
a snort2shoki, a script for converting snort signatures for use with
shoki.
An example of how to use it (use your favourite web browser if you don't
have wget(1)):
# mkdir /usr/local/shoki/conf/snort
# cd /usr/local/shoki/tmp
# wget http://www.snort.org/dl/rules/snortrules-stable.tar.gz
# tar -zxf snortrules-stable.tar.gz
# /usr/local/shoki/bin/snort2shoki -d /usr/local/shoki/tmp/rules \
-W /usr/local/shoki/conf/snort
# rm -rf /usr/local/shoki/tmp/rules
# rm snortrules-stable.tar.gz
Having done this, you need to uncomment the line
in /usr/local/shoki/conf/lexer_filterlist.conf that contains
snort_converted.conf .
You -will- want to verify the converted rules by runningtest data. There
will almost certainly be some conversion errors. I.e.,
from the top of the shoki source tree, you can try:
# /usr/local/shoki/bin/lexer -L - -r ./test/test_dump.gz \
-F /usr/local/shoki/conf/snort/snort_converted.conf
...which will run the converted rules against the test data included in
the shoki distribution.
If lexer(1) generates errors, you'll have to either edit the offending
rules by hand or comment them out. Most of these errors will probably
be caused by the presence of variables in snort rules. I.e., you might
get an error like:
ERROR: compiling filter SHELLCODERULES978: \
"ip and (dst port $shellcode_ports)"
The `SHELLCODERULES978' string is an unique filter ID and can be used to
identify the offending signature. In this case all the signatures in
/usr/local/shoki/conf/snort/snort_shellcode.rules contain the variable,
so you probably want to either comment the snort_shellcode.rules line
out of snort_converted.conf or do a global search and replace in your
favourite editor to twiddle the lines containing `$shellcode_ports' to
your liking.
If you have shoki signatures in the old (pre-0.3.0) format and want to use
them with shoki 0.3.0 or later, you can convert them with the
old2new script.
If the filter list you want to convert is called
/usr/local/shoki/conf/parser_local.conf and you want to save the
converted rules to /usr/local/shoki/conf/lexer_converted.conf:
# /usr/local/shoki/bin/old2new -f /usr/local/shoki/conf/parser_local.conf > \
/usr/local/shoki/conf/lexer_converted.conf
In general, the filters should be converted with no problems: the
old and new formats are structurally different, but by and large the
current functionality is a superset of the old functionality. You
may nevertheless want to hand-verify the new filter list before using
it in production.
There are four mechanisms for alert notification built into shoki: logging
to a file, logging via syslog(2), email, and jabber.
To enable logging to a flat text log file, simply set the ALERT_LOG
variable in /etc/shoki.conf. New alerts will be appended to
the specified file, which will be created if it doesn't already exist.
If the ALERT_LOG variable is commented out, no log file will
be used.
Output will look something like:
[Tue Feb 24 18:51:45 2004] 1193 25/02/04 02:51:16 Doctrine Foo 2003-10-02 22:43:28-07 1.1.1.1:38932 -> 2.2.2.2:25 6 (INFO)
In this example:
- [Tue Feb 24 18:51:45 2004]
-
This timestamp is the time the alert was written to the logfile.
- 1193
-
This is the alert number, which is a unique sequence number. This
comes straight from the alerts table of the shoki database.
- 25/02/04 02:51:16
-
This is the timestamp of the alert itself. This is the time the alert
was inserted into the alerts table of the shoki database. This
is generally going to generated by ooda(8).
- Doctrine Foo 2003-10-02 22:43:28-07 1.1.1.1:38932 -> 2.2.2.2:25 6
-
This is the text of the alert. The timestamp here is the timestamp of the
stimulus event which triggered the alert. Typically, this will be the
time on the event as reported by dlex(8), but the text of
the alert is actually inserted into the alerts table by
ooda(8).
- (INFO)
-
This is the severity level of the alert. For most alerts, this will be
the severity level defined in the doctrine which generated the alert.
To enable logging via syslog(2), set the SYSLOG_FACILITY
variable in /etc/shoki.conf to a valid syslog(2) facility.
New alerts will be logged via syslog(2) to the given facility
with the ALERT log level.
If the SYSLOG_FACILITY variable is commented out, no alerts will
be logged via syslog(2).
Output will look something like:
Feb 24 18:51:45 schadenfreude shoki_alerts[11054]: 1193 25/02/04 02:51:16 Doctrine Foo 2003-10-02 22:43:28-07 1.1.1.1:38932 -> 2.2.2.2:25 6 (INFO)
In this example:
- Feb 24 18:51:45 schadenfreude shoki_alerts[11054]:
-
This is the stuff added by syslogd(8) itself. Note that
by default, shoki widgets will use the process name shoki_alerts
when logging alerts, independent of the actual process name of the reporting
widget. This is done to make alert aggregation easier.
-
The timestamp here is the time the alert was submitted via syslog(2).
The rest of the format is the same as that described in the section above.
Alert notification via email is handled by the reporter script
on the aggregator. In order to enable this notification method, you'll
have to do two things:
- Add recipients to the EMAIL variable in /etc/shoki.conf
-
You may wish to edit ./shoki.conf.in in the shoki source tree
before running ./configure and doing a make install (which
convert ./shoki.conf.in to ./shoki.conf and copy it
to /etc/shoki.conf, respectively). Otherwise you'll have to
re-edit /etc/shoki.conf every time you do a make install.
-
The format of the EMAIL variable is documented in the config
file itself. It's either a single email address, or a double quoted,
space-delimited list of email addresses.
- Add the same recipients' GPG key to the shoki user's keyring
-
Consult the GPG documentation for how to do this. Short version:
as the shoki user, do a gpg --import on all the recipients'
public keys.
-
Note that if the EMAIL variable points to a single address (i.e.,
a mailing list), all of the people who want to be able to read the
alert notifications will have to share the same GPG key. If all this
key is used for is encrypting the alert emails (and the encryption is
understood to be in place to prevent eavesdropping on the email in
transit), this is probably safe.
-
Alternately, if you don't care if the alerts are sent in the clear, you
can just edit the reporter script to send the email without
encrypting it first.
If you have a jabber 2.x server (or are willing to set one up), you can
use shoki_sez(8) to send alert notifications via the jabber
protocol to your IM client. In order to do this, you'll have to:
- Set up a jabber 2.x server
-
Consult www.jabber.org for details
on how to accomplish this.
- Create a shoki_sez user
-
Consult your jabber server documentation for information on how to do
this.
- Add access controls for the shoki_sez user
-
THIS IS IMPORTANT. There are no access controls built into
shoki_sez(8). This means you want to configure the shoki_sez
user to only accept messages from specific users. Once again, consult
the jabber server documentation on how to accomplish this.
-
In gaim(1) you can log on as the shoki_sez user, select
Privacy under the Tools menu, change Allow all users
to contact me to Allow only the users below, and then
manually enter the IM IDs of all the analysts who should be allowed
to have access to the alert data.
- Edit /usr/local/shoki/etc/shoki_sez.conf
-
You'll want to define/check the values of the variables:
- jabber_luser set to the name of the shoki_sez user you just created
- jabber_passwd set to the passwd for the shoki_sez user
- jabber_server set to the hostname of the jabber server
- jabber_contact set to the jabber ID of an analyst you want to receive the alerts. add multiple instances of this declaration to notify multiple IDs
- Start up shoki_sez(8)
-
By default, it will fork and run in the background.
-
You may want to set up a script to start shoki_sez(8) at boot
time.
The best, most up-to-date information about writing shoki filters is
usually the shoki.filters(5) manpage. It should give a
complete listing of all the options supported by the version of shoki
it came with. It generally also has examples of filters using most
of the common options.
The information in this document is intended to be more of a tutorial
for writing shoki filters. If you've never written shoki filters
before, this is probably what you want. If you're just interested in
a quick reference for the shoki filter rule format, consult the
shoki.filters(5) manpage instead.
Let's take a look at a very simple shoki filter rule:
filter
{
id = "FOO1";
name = "Simple IP filter";
action = LOG;
pcap = "ip";
};
Note that non-quoted whitespace is ignored, so this is equivalent to:
filter { id = "FOO1"; name = "Simple IP filter"; action = LOG; pcap = "ip"; };
This filter will match all IP packets. Let's go through it piece by
piece.
- filter { };
-
All filters are of this general form: the word `filter',
a bunch of filter stuff (which we'll cover in more
detail below) enclosed in curly braces, and a semicolon at the end.
- id = "FOO1";
-
This sets the filter's unique ID to the literal FOO1. This is
used almost entirely for disambiguation: whenever shoki needs to identify
a specific filter, it will use the filter's ID. Every filter is required
to have an ID.
-
This also shows the basic format of filter options: the name of
the option, an equal sign, the value you're setting for the option, then
a semicolon. In general, whenever you're setting a alphanumeric value
the argument should be in double quotes. For more details, consult
the shoki.filters(5) manpage.
- name = "Simple IP filter";
-
The filter name is the human-readable message that will be associated
with packets matching this filter. If you ran this filter against a
bunch of data using lexer(1), for example, it would log
the message "Simple IP filter" for each IP packet.
- action = LOG;
-
This sets the action taken when this filter matches. In general, you'll
probably write LOG rules (which just match a pcap expression)
and SEARCH rules (which match both a pcap expression and one or
more search expressions).
-
Note that there are no double quotes around the action.
- pcap = "ip";
-
This defines the pcap expression for the filter. Any valid pcap expression
is acceptable. In this example (and any other filter with the LOG
action), matching the pcap expression will cause the filter to match.
Let's try running this filter against some test data.
Open up your favourite editor, type in this filter, and then save
it to a file (i.e., /tmp/sample.conf). Then, from the top of the shoki
source tree, type:
# lexer -r test/test_dump.gz -L - -F /tmp/sample.conf | head
The output should be:
Simple IP filter 975745794.459135 192.168.1.5:0 -> 192.168.1.10:0 1
Simple IP filter 975745794.459171 192.168.1.5:45951 -> 192.168.1.10:80 6
Simple IP filter 975745794.459182 192.168.1.10:0 -> 192.168.1.5:0 1
Simple IP filter 975745794.459208 192.168.1.10:80 -> 192.168.1.5:45951 6
Simple IP filter 975745794.540598 192.168.1.5:45931 -> 192.168.1.10:1059 6
Simple IP filter 975745794.540626 192.168.1.10:1059 -> 192.168.1.5:45931 6
Simple IP filter 975745794.540638 192.168.1.5:45931 -> 192.168.1.10:1039 6
Simple IP filter 975745794.540648 192.168.1.5:45931 -> 192.168.1.10:1207 6
Simple IP filter 975745794.540671 192.168.1.5:45931 -> 192.168.1.10:1257 6
Simple IP filter 975745794.540683 192.168.1.10:1039 -> 192.168.1.5:45931 6
The default output format for lexer(1) is: filter name, timestamp,
source address, source port, destination address, destination port, IP
protocol. The src_ip:sport > dst_ip:dport ip_proto data is sometimes
(somewhat misleadingly) called the `IP quad'. At any rate, matching all
IP packets isn't terribly interesting, so let's edit our filter to be:
filter
{
id = "FOO2";
name = "Simple port filter";
action = LOG;
pcap = "ip and port 45951";
};
Running the lexer with this filter on the same data will output:
Simple Port filter 975745794.459171 192.168.1.5:45951 -> 192.168.1.10:80 6
Simple Port filter 975745794.459208 192.168.1.10:80 -> 192.168.1.5:45951 6
Consider a simple DMZ consisting of a mail server, a DNS server, and
a web server:
![[DMZ]](dmz.gif)
We'll ignore the NIDS box and the firewall for the time being; we're
just going to worry about writing filters for traffic involving the
three servers. Let's go ahead an list some information about each of the
servers:
- SMTP server
-
IP address: 10.1.1.10
-
Open ports: 25/TCP
-
Notes: This machine should allow incoming and outgoing mail to any other host
- DNS server
-
IP address: 10.1.1.20
-
Open ports: 53/TCP (see Notes below), 53/UDP
-
Notes: This machine should allow DNS zone transfers from two other DNS
servers whose IP addresses are 10.2.2.15 and 10.3.3.15. It should allow
incoming and outgoing DNS queries to any host.
- HTTP server
-
IP address: 10.1.1.30
-
Open ports: 80/TCP
-
Notes: This machine should allow incoming web traffic from any host
Let's consider web server first. If all it's doing is serving web pages,
it should never see any traffic that isn't on port 80 (we'll ignore
administrative traffic---i.e., ssh---for this example). In addition, since
the web server is the only machine in the DMZ listening on port 80, it's
they only host that should see any traffic on this port. These two
facts form the basis for a pretty good starting point for a set of NIDS
filter rules.
First, we'll write a rule that matches all traffic directed at the web
server that isn't on port 80:
filter
{
id = "DMZWEB01";
name = "Non-HTTP traffic to web server";
action = LOG;
pcap = "dst host 10.1.1.30 and not (tcp and dst port 80)";
severity = WARNING;
};
The ID is just an arbitrary (but unique) identifier for the filter. It
doesn't really have to be human-readable, but it helps to have some sort
of pattern to your filter IDs. The name is intended to human
readable; remember that it's what will be reported when the filter is
matched. The action is LOG, which means a match of the pcap
expression is a match of this filter. The pcap expression is
just that: a vanilla pcap expression.
Setting the severity
to WARNING is a judgement call. The default severity is INFO,
so this filter will generate events of greater-than-default severity. The
rationale is that this filter is targetted: it reflects something meaningful
about the underlying structure of the network. Depending on how you're
handling events on the back end, tweaking event severity may or may not
make sense. We'll look at event processing in greater detail later.
If the pcap expression doesn't
make sense to you, consult the tcpdump(1) manpage for more details
about pcap expression syntax. If anything else in the filter doesn't make
sense, consult the shoki.filters(5) manpage.
To implement our second rule (web traffic to any host beside the web
server):
filter
{
id = "DMZWEB02";
name = "HTTP traffic to non-web server";
action = LOG;
pcap = "(dst net 10.1.1.0 mask 255.255.255.0) and
(not host 10.1.1.30) and tcp and (dst port 80)";
severity = WARNING;
};
We add the (dst net 10.1.1.0 mask 255.255.255.0) so we won't
catch any outbound web traffic. Otherwise, there's nothing
clever going on here; it's just meat 'n potatoes pcap in a shoki filter.
Moving on to the mail server, we can obviously set up analogous rules:
filter
{
id = "DMZMAIL01";
name = "Non-SMTP traffic to MTA";
action = LOG;
pcap = "dst host 10.1.1.10 and not (tcp and dst port 25)";
severity = WARNING;
};
filter
{
id = "DMZMAIL02";
name = "SMTP traffic to non-MTA";
action = LOG:
pcap = "(dst net 10.1.1.0 mask 255.255.255.0) and
(not host 10.1.1.10) and tcp and (dst port 25)";
severity = WARNING;
};
Nothing new so far. But if we ran a bunch of traffic through these
filter rules, we'd probably notice a whole lot of traffic to port 113
getting caught by the first rule (DMZMAIL01). Since ident
traffic is pretty innocuous, we'll want to tweak our rules to accomodate
it. So let's get rid of DMZMAIL01 and replace it with two new
rules:
filter
{
id = "DMZMAIL01A";
name = "Non-SMTP traffic to MTA";
action = LOG;
pcap = "dst host 10.1.1.10 and (not tcp and dst port 25)
and (not dst port 113)";
severity = WARNING;
};
filter
{
id = "DMZMAIL01B";
name = "ident traffic to MTA";
action = LOG;
pcap = "dst host 10.1.1.10 and (dst port 113)";
severity = DEBUG;
};
The second rule is really just presented for completeness. In reality,
you probably would want to keep the first rule (DMZMAIL01A) and
ditch the second (DMZMAIL01B). Alternately, you could add the
second rule and configure widgets like lexer(1) to only log
events of INFO or higher priority by default. This would allow
you to run lexer(1) by hand with different arguments to
catch these events (i.e., if you're trying to debug a problem or
some such).
Finally, let's turn our attention to the DNS server. At this point,
you should know everything you need to know in order to work the
rules out for yourself. Really, the only complications in any of
the filters we've looked at so far are in the pcap expressions, not in
anything that's really shoki-specific. Anyway, here is one way to write
the DNS server rules:
filter
{
id = "DMZDNS01";
name = "Non-DNS traffic to DNS server";
action = LOG;
pcap = "dst host 10.1.1.20 and not (udp and port 53)
and not (tcp and dst port 53 and (src host 10.2.2.15 or
src host 10.3.3.15))";
severity = WARNING;
};
filter
{
id = "DMZDNS02";
name = "DNS traffic to non-DNS server";
action = LOG;
pcap = "(dst net 10.1.1.0 mask 255.255.255.0) and (not host 10.1.1.20)
and (dst port 53) and (udp or tcp)";
severity = WARNING;
};
So far all we've looked at are LOG filter rules. Since LOG
match (or don't) entirely on the basis of the filter's pcap expression,
all the filters we've looked so far have been based on header information;
the data segment of the packets are completely ignored.
This is not cooincidental; shoki is strongly biased toward traffic analysis
rather than content inspection. That being said, shoki filters offer
powerful mechanisms for examining the packet contents. These mechanisms
involve the SEARCH action, and literal, hex, regex, and optionally
PCRE search expressions. Here are some examples, with brief explanations:
Match TCP packets containing the literal string foobar:
filter
{
id = "EX2A";
name = "Example 2a (TCP search)";
action = SEARCH;
literal = "foobar";
pcap = "tcp";
};
Match TCP packets to port 80 containing the hex literal 485454502f312e31:
filter
{
id = "EX2B";
name = "Example 2b (TCP hex search)";
action = SEARCH;
hex = "485454502f312e31";
pcap = "tcp and dst port 80";
};
Match TCP packets to ports 80 and 443 containing http:// or
https://:
filter
{
id = "EX2C";
name = "Example 2c (TCP regex search)";
action = SEARCH;
regex = "http[s]*://";
pcap = "tcp and (dst port 80 or dst port 443)";
};
In addition, shoki filters can use the THRESHOLD and SCAN
actions which will match when multiple packets matching the given
criteria are seen. Some examples:
Match when five (5) TCP packets with only the SYN flag set are seen
within three (3) seconds:
filter
{
id = "EX3";
name = "Example 3 (SYN threshold)";
pcap = "tcp[13] == 2";
action = THRESHOLD;
threshold = 5;
duration = 3;
};
Match when TCP or UDP packets with seven (7) different destination ports
are directed at 192.168.1.10 within four (4) seconds:
filter
{
name = "Example 4 (Port scan)";
id = "EX4";
pcap = "(tcp or udp) and dst host 192.168.1.10";
action = SCAN;
scan_field = "TH_DPORT";
threshold = 7;
duration = 4;
};
Finally, we can write filter which match TCP or IP options. For example,
here's a filter which matches TCP packet with the MAXSEG,
SACK_OK, and TCPOPT_TS TCP option set (in that order):
filter
{
name = "Example 5 (TCP options)";
id = "EX5";
action = LOG;
pcap = "tcp";
tcp_options = "MAXSEG;SACK_OK;TCPOPT_TS";
};
All of the examples in this section are straight from the
shoki.filters(5) manpage. This manpage is a comprehensive
guide to the filter syntax, and it includes many details not covered
in this tutorial.
So far, all the filters we've seen have involved single packets or (in
the case of SCAN and THRESHOLD filters) small groups of
similar packets.
That's pretty much the limit to what you can do with simple filters. To
test for more elaborate traffic patterns, you'll have to use other means.
One of the mechanisms shoki provides for advanced pattern matching involves
expressions called doctrines. Think of doctrines as sets of rules
for generating dynamic filter expressions on the fly, based on characteristics
of input traffic.
Let's consider a specific example to get a feel for how doctrines work.
Imagine that you're seeing a large volume of ICMP packets on one
of your networks. Looking more closely at the traffic, you discover
that there are a large number of ICMP type 3 (UNREACHable) errors, and
that many of the encapsulated IP headers do not correspond to any traffic
that actually originated on your network. In other words, you're seeing
ICMP errors for attempted connections that you didn't make. This,
incidentally, probably means that someone is sending spoofed traffic with
source IPs that you own.
To set up shoki to report this sort of behaviour, we'll first need to
write a standard shoki filter rule to catch the ICMP packets. This is
straighforward:
filter
{
id = "ICMPUNREACH";
name = "ICMP type 3 (UNREACHable)";
action = LOG;
pcap = "icmp[icmptype] == 3";
};
None of this should be new. Testing for the rest of the conditions---that
a packet corresponding to the encapsulated IP header in the ICMP error
message was not sent---is trickier. Indeed, this is something
that you cannot accomplish using the standard shoki filter logic (or
the filter logic of most NIDS, for that matter). The way we accomplish
it is by writing a simple shoki doctrine:
doctrine
{
doctrine_name = "ICMP test doctrine";
doctrine_id = "DOCICMP01";
doctrine_window = 10.0;
filter
{
id = "DOCICMP01-01";
name = "Missing ICMP UNREACH stimulus packet";
backfield = "id";
backref = "ICMPUNREACH";
pcap = "src host ICMP_ESRC and dst host ICMP_EDST";
action = INVERSE;
terminal;
};
};
Looking at the individual components of the doctrine:
- doctrine { };
-
This is the general form of the doctrine declaration; analogous to
a filter declaration.
- doctrine_name = "ICMP test doctrine";
-
This is just a human-readable label for the doctrine. Note that this
is not necessarily what is logged when the doctrine matches. Indeed,
in the present example, it is not. This will be discussed
in more detail in the following section.
- doctrine_id = "DOCICMP01";
-
A unique identifier for the doctrine. Follows the same rules as
filter IDs.
- doctrine_window = 10.0;
-
Defines a duration (in seconds) over which all the doctrine conditions
must be satisfied in order for the doctrine to match.
- filter = { };
-
With a couple of exceptions, the syntax of a filter within a doctrine
is the same as a normal shoki filter expression. Consult the
shoki.doctrine(5) manpage for details on the differences. For
the present example, the differences are discussed below.
- id = "DOCICMP01-01";
- name = "Missing ICMP UNREACH stimulus packet";
-
The declarations define a unique ID and name for this filter, just as
they would in a normal filter expression.
- backfield = "id";
- backref = "ICMPUNREACH";
-
These two declarations define backward reference criteria for this
filter. In this case, the filter references packets which match the
filter with the unique id ICMPUNREACH (which is the filter we
defined above).
-
The backward reference determines which packets will be used as input
into this filter. In this case, only packets matching our ICMPUNREACH
filter will be passed to this doctrine filter (DOCICMP-01).
- pcap = "src host ICMP_ESRC and dst host ICMP_EDST";
-
This is the interesting bit. This defines the pcap expression for this
filter. The tokens ICMP_ESRC and ICMP_EDST will be replaced
by the source IP address and destination IP address (respectively) from
the IP header encapsulated in the ICMP error messages passed as input
to this filter.
-
In the general case, the tokens which appear in the pcap expression of
a doctrine filter will be replaced by the corresponding values from the
packets passed to the filter by the backward reference criteria. A list
of valid tokens is given in the shoki.doctrine(5) manpage.
- action = INVERSE;
-
The INVERSE action is a standard shoki filter action (although
one we have not previously seen in this manual). It causes the filter
to match when no packets matching the filter expression are found in
the input data. In this example, that means this filter will match
if no packets matching the pcap expression are found.
- terminal;
-
This signifies that doctrine will match when this filter is matched. This
isn't terribly interesting in a doctrine with one filter. It will probably
make more sense when we look at more complex doctrines in a bit.
Back in early 2000 DDoS attacks were all the rage. At the time, Dave
Dittrich wrote a tool called dds which scanned for three popular DDos
agents (trinoo, TFN, and stacheldraht). The scanner generated three
packets per destination address:
- An ICMP_ECHOREPLY containing the string gesundheit!
- An ICMP_ECHOREPLY with an IP ID one greater than the IP ID of the
gesundheit! packet
- An UDP packet with an IP ID one greater than the IP ID of the second
ICMP packet and an 11 byte long data segment
Let's look at a doctrine that will match this traffic:
filter
{
id = "DDS01-1";
name = "DDS gesundheit packet";
action = SEARCH;
literal = "gesundheit!";
pcap = "icmp[icmptype] == 0";
};
doctrine
{
doctrine_name = "DDS scanner";
doctrine_id = "DOCDDS01";
doctrine_window = 10.0;
log_dname;
filter
{
id = "DOCDDS01-01";
name = "DDS ICMP packet";
backfield = "id";
backref = "DDS01-1";
pcap = "(icmp[icmptype] == 0) and (src host IP_SRC) and
(ip[4:2] == IP_ID + 1)";
action = LOG;
};
filter
{
id = "DOCDDS01-02";
name = "DDS UDP packet";
backfield = "id";
backref = "DOCDDS01-01";
pcap = "udp and (src host IP_SRC) and (ip[4:2] == IP_ID + 1)
and (ip[2:2] == 39)";
action = LOG;
terminal;
};
};
There are a couple of things worth noting here:
- log_dname;
-
The log_dname directive specifies that the doctrine name should
be logged when the doctrine matches. By default, the name of the last
matching filter is used instead. In this case, that means that any alerts
this doctrine produces will include the text DDS scanner (the
doctrine name) instead of DDS UDP packet (the name of the only
terminal filter rule).
- terminal;
-
Notice that the first filter (DOCDDS01-01) does not contain a
terminal declaration. This means that no alert will be generated
if this filter matches; the only result of such a match will be a
new filter being written to the doctrine_filters table of the
database.
-
The second filter (DOCDDS01-02) does contain the a terminal
declaration. As a result, an alert will be logged whenever this filter
is matched.
Note that the example above is a complete, valid doctrine file. I.e.,
you could save it to a file /usr/local/shoki/conf/dds.doctrine,
then add the following line to both
the /usr/local/shoki/conf/ooda_doctrine.conf
and /usr/local/shoki/conf/lexer_filterlist.conf:
include /usr/local/shoki/conf/dds.doctrine
You could also append the input filter (DDS01-1) to another
filter list read by lexer(1), leave it out of the
dds.doctrine file, and only include the doctrine file
from ooda_doctrine.conf.
The point here is that lexer(1)
needs to see the input filter (DDS01-1 in this example), but
ooda(8) does not. Conversely, ooda(8) needs to see
the doctrine declaration, but lexer(1) does not.
In general, it's probably a good idea to include filters in the doctrine
file if the only thing they're used for is input into the doctrine. If
they're used for other things (i.e., if they're standard attack signatures),
then they should probably be added to wherever you keep your other
attack signatures (i.e., /usr/local/shoki/conf/lexer_local.conf).
The doctrine logic involves three moving parts: the ooda(8) widget,
the dlex(8) widget, and the postgres database. Without going into
all the details, the process works something like this:
- ooda(8)
-
At startup, ooda(8) reads a list of doctrines from
/usr/local/shoki/conf/ooda_doctrine.conf
-
It then listens to the events table of the shoki database.
-
When new events are added, ooda(8) compares them to its doctrine
rules. If an event matches a terminal rule, ooda(8) writes
an alert to the alerts table. If the matching rule is a nonterminal,
a new filter will be written to the doctrine_filters table (the
new filter content will be dictated by the pcap declaration of
the doctrine rule).
- dlex(8)
-
At startup, dlex(8) listens to the doctrine_filters table
of the shoki database.
-
When new filters are added, dlex(8) runs the filters against
any relevant dumpfiles listed in the dumpfiles table of the database.
Matching packets will be logged to the events table.
This is obviously an iterative process: ooda(8) reading
events, writing doctrine_filters; dlex(8) reading
doctrine_filters and writing events.
This section defines various special terms used throughout the shoki
documentation.
- aggregator
-
The centralised server to which data (i.e., packet
dumps) are copied. This is also where most of
the shoki widgets live: lexer(1), ooda(8), dlex(8),
and most of the sh/perl scripts.
- alert
-
An alert is, structurally, a discrete hunk of
information that shoki will attempt to bring to
the attention of the analyst. In shoki, alerts
get written to the alerts table in the shoki database.
From there, they are collected by alerter widgets (e.g. shoki_sez(8)),
which in turn notify the analyst (i.e., in email or via the Jabber protocol).
-
Conceptually, an alert is (or should be) an indication
that some high-level condition exists. I.e.,
a host has been compromised or an attack is in
progress.
-
Compare `event', below.
- analysis
-
The process(-es) by which low-level events are used
to infer the existence of higher-level conditions.
Looking at a raw data stream and noticing a packet
matching some signature foo is not analysis (in
this usage of the term). Correlating an inbound
packet matching foo with a new outbound connection
to the source of the packet matching foo is.
-
In shoki, most of the (automated) analysis is
done by ooda(8), using rules enunciated in
doctrine files.
- analyst
-
The consumer of the information output by shoki.
- asset
-
A resource, typically something like a machine
(router, firewall, or host, for example) or a
capability (i.e., a web server).
-
Assets are tracked by shoki to help evaluate the
criticality of some types of events. For example,
an IIS exploit directed at an IIS server is probably
more interesting than an IIS exploit directed
at an apache server, which in turn is more interesting
than the same exploit directed at a machine running
no web server at all.
- categorisation
-
The process of identifying events from the captured
data stream. In general, that means running lexer(1)
against a dumpfile with a large set of signatures.
This is the bulk of what most NIDS do---identify
packets matching signatures.
- event
-
Discrete information emitted by any of the
categorisation widgets. In most cases, events
will be individual log lines coming out of the lexer(1)
widget. I.e., a timestamp, a signature name, and
an IP quad.
-
Conceptually, think of events as defined tokens in the
raw network data steam. The content of any given
event is typically that data matching some
clearly enunciated criteria has been observed. Most
NIDS add the connotation that some higher-level
condition has been satisfied (i.e., an exploit
has been attempted). No such connotation is (by
default) associated with events in shoki.
-
Compare `alert', above.
- sensor
-
Used to refer both to the sensor(8) widget (which
uses libpcap to capture network data and write
it to a dumpfile) and to the machine on which the
widget runs.
-
Unlike many other NIDS systems, the sensor does
little or no actual categorisation or analysis
of data---its purpose is to get packets off the
wire and onto disk. From the sensor, data are
collected by the aggregator, where categorisation
and analysis occurs.
- vulnerability
-
In shoki, known vulnerabilities are expressed
as references to standard vulnerability databases (i.e,
CVE or CAN numbers). Vulnerability references
in events are correlated to vulnerability references
in assets.
-
These references are associated with filter rules
in shoki filter files In addition, vulnerability
data can be associated with asset data by importing
nessus reports (via the nessus2shoki script).
Vulnerability data are used by shoki to help
evaluate the criticality of certain sorts of events.
This is an overview of the basic topology of the shoki NIDS. It is indended
to give the analyst an idea of how data is processed by shoki
from the time it is pulled off the wire to when it shows up as an alert.
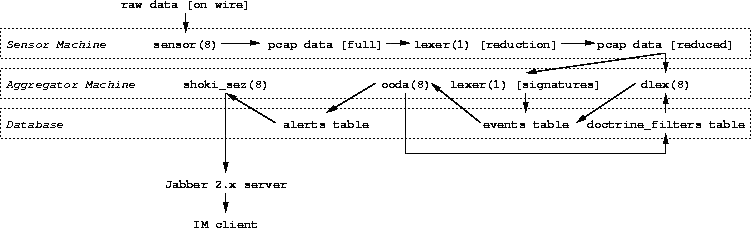
The Sensor
Flow of data on the sensor machine is straightforward:
- Packets are captured off the wire by the sensor(8) widget and
written to pcap dumpfiles
- Each packet dump is run through lexer(1) with a simplified set of
filter rules to produce a smaller dumpfile
- The aggregator machine collects the reduced dumpfiles via rsync(1).
The Aggregator and Database
Data flow through the aggregator machine and database are somewhat more
complicated:
- Dumpfiles collected from the sensor machine are passed through
lexer(1) running with a full set of NIDS signatures, logging matches
to the events table of the shoki database.
- The ooda(8) widget listens to the events table, and passes
new events through its doctrines (see shoki.doctrine(5) for details),
potentially writing new filters to the doctrine_filters table or
writing alerts to the alerts table.
- The dlex(8) widget listens to the doctrine_filters table,
and runs any new filters against the same packet dumps read
by lexer(1) in step 1 above, potentially writing new events to
the events table (which will be seen by ooda(8), effectively
looping back to step 2 above).
- The shoki_sez(8) widget listens to thei alerts table,
forwarding any new alerts to its contact list via the Jabber protocol.
To be added Real Soon Now.
These are just some notes on the assumptions made in the shoki implementation.
Eventually this should be converted into something a little more formal
and complete.
- Raw data is untrusted
-
By default, most shoki widgets will chroot(2) and setuid(2) to a
nonprivileged luser before processing raw network data. This is
done regardless of whether the data have been processed by one or
more shoki widgets previously.
- Config files are trusted
-
Config files are checked for syntactic correctness, but are not treated
as potential attack vectors. The assumption is that if an evildoer can twiddle
your NIDS config files, they can twiddle the raw data as well.
- The /usr/local/shoki directory is assumed to not be public
-
It is assumed that the shoki user will have access to the directory where
the binaries, config files, and data live but that this directory will
not be world accessable.
-
In particular, it is assumed that things like predictable file names
are safe (and so can, for example, be appended to without checking).
- Encryption in transport is the responsibility of the application doing
the transportation
-
The collector script relies on ssh(1) to encrypt the
data being collected.
-
Widgets that are Postgres-aware will rely on the Postgres
libraries to encrypt pgsql connections. In general, the pgsql-aware
widgets actually connect to the database on a local UNIX socket by
default, so this should only be a concern if you're running such widgets
anywhere other than the database machine.
-
The shoki_sez(8) widget relies on the jabber protocol for
encryption. Most distributions support TLS by default; this is assumed
to be adequate. In other words, the encryption is intended to prevent
unintentional disclosure of alert data to eavesdroppers.
This is intended to be a simple statement of the general design philosophy
shoki is intended to embody.
It is worth noting that second and third desiderata exist in balance
with each other; and the fourth and fifth, and sixth and seventh. All
of these in turn are balanced against the first desideratum. Or
that's the theory, at any rate.
- All other things being equal, the simpler system is better.
- Knowing about your own network is more important than knowing about
your opponents' tools.
In other words: if you have a dozen signatures which you've crafted
to model the expected behaviour of your network and 1,500 signatures
which match various attack signatures, the former dozen will be far
more likely to tell you useful things about your network than the latter
1,500.
The common belief (or at least the common practice) is the more signatures
the better. This, by and large, is bunk.
- Learning about your opponents' tools and motivations through side
channels is better than attempting to deduce them through traffic
analysis.
In general, reverse engineering a data stream, potentially one which
has been intentionally obfuscated, to determine the intent of the originator
of the data should be considered to be an endeavour of last resort.
In other words, attack methodologies which can be recognised through
comparison with reference data (e.g., a vulnerability database) should
be.
- Never collect data you're not interested in analysing. Never analyse
data you're not interested in acting on.
- It is better to collect data and ignore it than to
ignore data and wish you'd collected it.
- If you have to do it twice, you'd better script it.
- Anyone relying entirely on automated analysis is living in a state
of sin.
[Shoki Homepage]
[shoki@meshuggeneh.net]